Reuse Jupyter Notebooks
Use Jupyter Notebooks as "Objects"¶
Jupyter Notebooks are great for data exploration, visualizing, documenting, prototyping and interacting with the code, but when it comes to creating a program out of a notebook or using the notebook in porduction they fall short. I often get myself copying cells from a notebook into a script so that I can run the code with command line arguments. There is no easy way to run a notebook and return a result from its execution, can't passing arguments to a notebook or running individual code cells programmatically. Have you ever wrapped a code cell to a function just so you want to call it in a loop with different parameters?
I wrote a small utility tool nbloader that enables code reusing from jupyter notebooks. With it, you can import a notebook as an object, pass variables to its namespace, run code cells and pull out variables from its namespace.
This tutorial will show you how to make your notebooks reusable with nbloader.
Install nbloader with pip¶
pip install nbloader --upgrade
Load a Notebook¶
from nbloader import Notebook
loaded_notebook = Notebook('test.ipynb')
The above command loads a notebook as an object. This can be done inside a jupyter notebook or a regular python script.
Run all cells¶
loaded_notebook.run_all()
After loaded_notebook.run_all() is called:
- The notebook is initialized with empty starting namespace.
- All cells of the loaded notebook are executed one after another by the order they are the file.
- All print statement or any other stdout from the loaded notebook will output.
- All warnings or errors will be raised unless caught.
- All variables from the loaded notebook's namespace will be accessible.
Here are the contents of loaded_notebook.ipynb¶
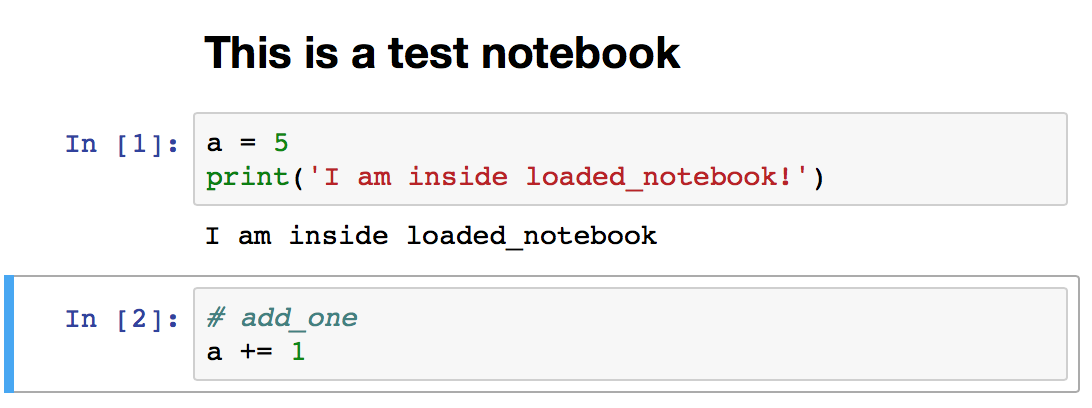
This is how you access the namespace of the loaded notebook:¶
loaded_notebook.ns['a']
The notebooks namespace is just a dict so if you try to get something that's not there will get an error.¶
loaded_notebook.ns['b']
Run individual cells if they are tagged.¶
loaded_notebook.run_tag('add_one')
print(loaded_notebook.ns['a'])
loaded_notebook.run_tag('add_one')
print(loaded_notebook.ns['a'])
If a cell has a comment on its first line it will become a tag. Cells can also be taged by the jupyter notebook tags.
This is how you access the notebook's namespace:¶
loaded_notebook.ns['a'] = 0
loaded_notebook.run_tag('add_one')
print(loaded_notebook.ns['a'])
The notebook namespace is what you would normally get with globals() when running the notebook the normal way with jupyter and since the namespace is just a dic, there is no performance penalty when passing large objects to the notebook. All the code from its cells is compiled and can be called in a loop with the speed of a regular function.
Example workflows:¶
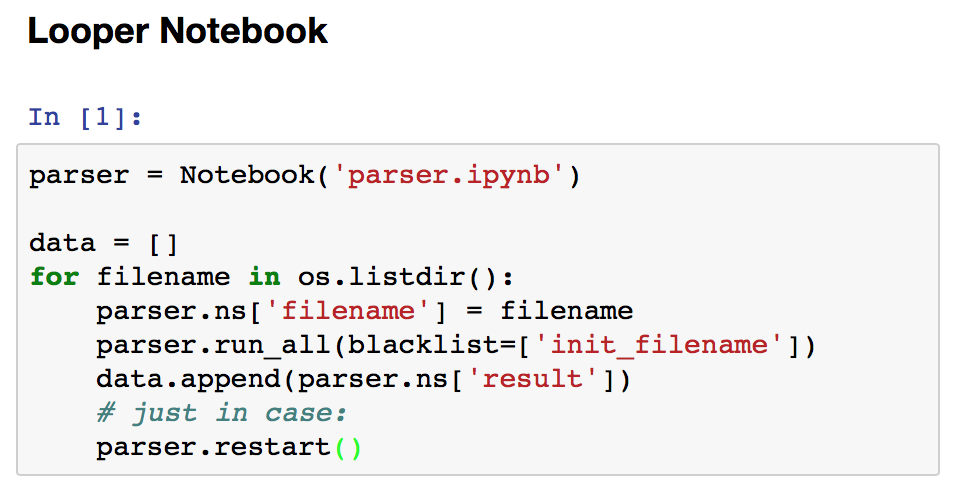
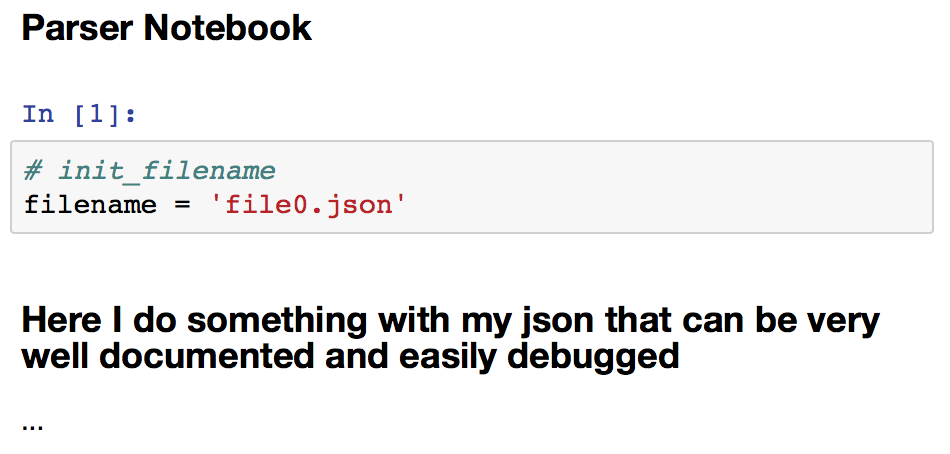
Create a notebook to parse one file and then call it in a loop when changing its namespace with a new value for filename.¶
|
|
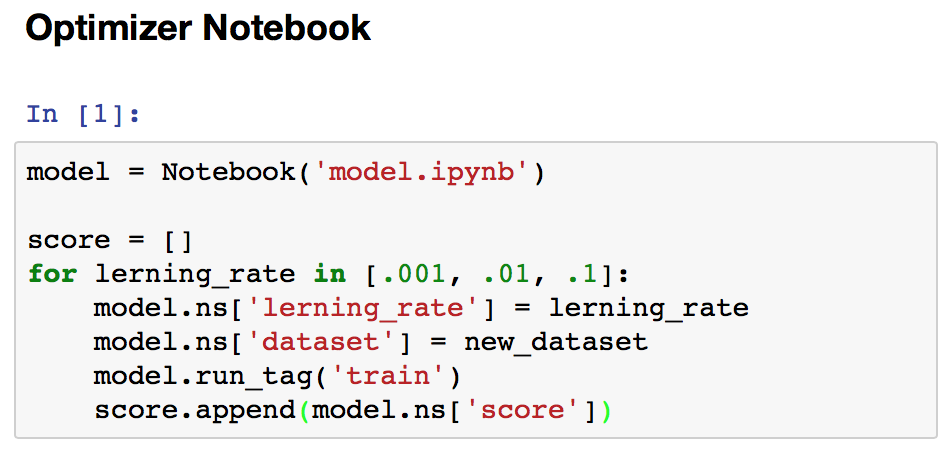
Create a notebook with a model and then optimize it with different parameters.¶
|
|
Added some magic_tags to make it act more like an a objects¶
- if a cell has a tag name
__init__will be run at initialization and when restarted. - if a cell has a tag name
__del__will be run when deleted (or not).
[Warning] on using best practices!¶
You may be tempted to load the current notebook and then loop a cell from it. I don't think this is a good practice.
Comments
Comments powered by Disqus